永不过时的八股,一些分析可能不太准确,但是一般的面试足够了。
常见面试题
底层数据结构,1.7 与 1.8 有何不同
1.7 采用数组+链表
1.8 采用数组+链表或红黑树
1.8 为何要用红黑树
如果某一数组位置的链表太长,是很影响 hashmap 性能的,转红黑树可以让查询效率快很多。
但是正常情况下,链表的长度是不会超过 8 的,一般长度都是 0-4,到 6 就已经非常少了。当有人恶意使用 DoS 攻击才会造成超过 8 的情况,导致我们链表过长,查询非常慢。 所以,红黑树用来避免 Dos 攻击。
为什么一上来不直接树化
在链表比较短的情况下,查询性能实际要比树更快,占内存也更小,所以一上来就树化是没必要的
何时会树化
链表长度超过树化阈值 8,数组长度大于等于64
何时退化
在扩容时如果拆分树时,树元素个数 <= 6 则会退化链表
remove 树节点时,移除前若 root、root.left、root.right、root.left.left 有一个为 null ,也会退化为链表
树化的阈值为何是 8
按照泊松分布,在默认负载因子 0.75 的情况下,长度超过 8 的链表出现的概率非常非常小,也就是为了让树化的几率足够小。
索引的计算方法
- 首先,计算对象的
hashCode() 再进行调用 HashMap 的
hash()方法进行二次哈希- 二次
hash()是为了综合高位数据,让哈希分布更为均匀
- 二次
- 最后
& (capacity – 1)得到索引
为什么要二次 hash
二次 hash 是为了配合 容量是 2 的 n 次幂 这一设计前提,如果 hash 表的容量不是 2 的 n 次幂,则不必二次 hash。容量是 2 的 n 次幂 这一设计计算索引效率更高,但 hash 的分散性就不好,需要二次 hash 来作弥补,没有采用这一设计的典型例子是 Hashtable
那为什么要用数组容量是 2 的 n 次幂
我们都知道,拿到对象的 hashcode 值后,需要对它与数组长度取模,但取模运算效率较低,可以采用另一个效率更高的位于运算方法,但前提是数组长度为 2 的 n 次幂。另外,扩容时重新计算索引效率更高, hash & oldCap == 0 的元素留在原来位置 ,剩下元素的新位置 = 旧位置 + 旧容量
HashMap底层结构
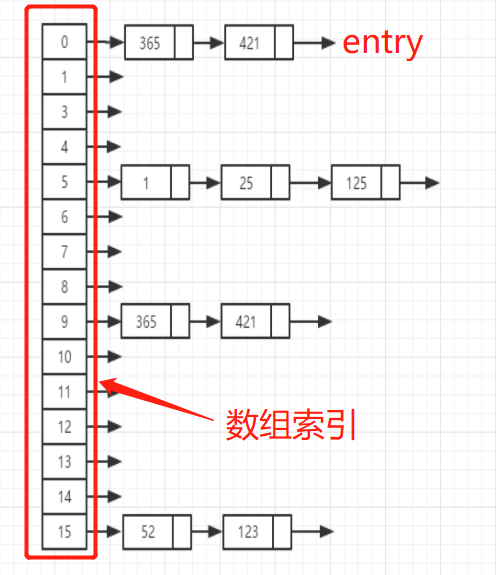
首先 HashMap 维护了一个数组,数组中存储的数据类型为 entry(键值对),也就是每个 key-value 键值对被称为一个 entry 实体。entry 类是一个单向链表结构,维护了一个 next 属性指向下一个 entry。每个 entry 要添加到 map 中,首先要计算 key 的 hashcode,对 hashcode 取模操作,根据结果(称为桶下表)来把 entry 存放在数组中对应的索引位置。jdk1.8 当某个数组索引位置上挂载的 entry 链表长度超过 8 时,先判断数组长度是否达到 64,未达到则先扩容数组为原来 2 倍(对应下文的扩容机制),达到 64 才就把链表转为红黑树,所以链表长度超过 8 但还没转红黑树的情况是存在的。(这段大家需要好好看源码才能理解更透彻)


TreeMap、TreeSet以及 jdk1.8 之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,二叉查找树在某些情况下会退化成一个线性结构。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) //MIN_TREEIFY_CAPACITY = 64
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}node 是 entry 的实现类。其中维护属性有 hash(记录hash值),key,value,next(指向下一个节点),然后重写了 equals()、hashCode() 方法。
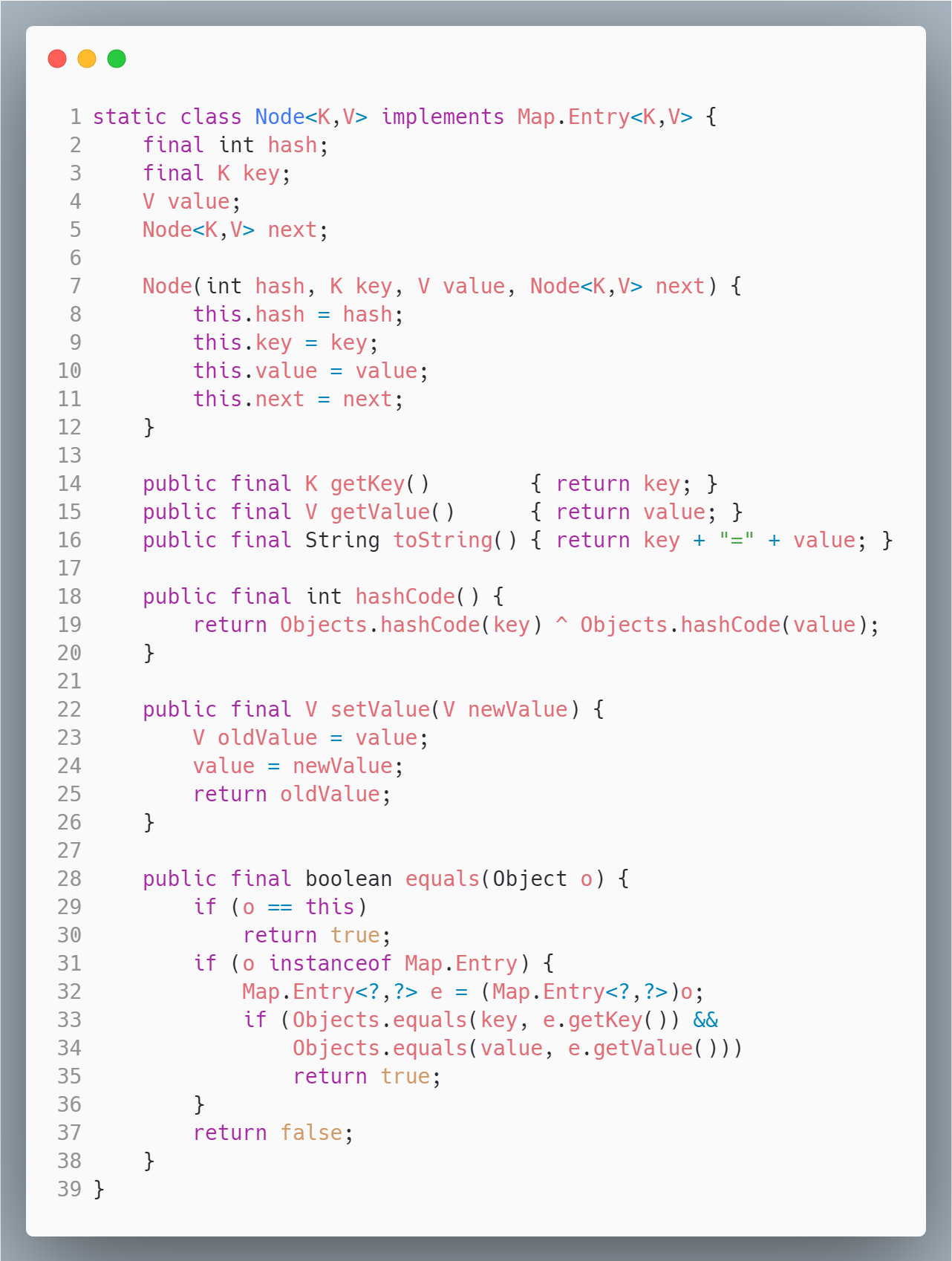
HashMap属性字段
table一个 Node[] 数组entrySet存放 map 中所有的 entry,便于遍历等操作sizetable 中被使用的数量modCount是一个计数器,主要记录 HashMap 操作的次数,比如 put 操作loadFactor负载因子,默认值是 0.75
另外,table,entrySet,size,modCount 使用了 transient 修饰,不让它们被序列化。
transient
这跟 Java 的序列化有关,我们都知道 Java 传输对象或者IO存储时需要把对象进行序列化处理,但是有些敏感字段我们不希望被序列化,不希望被传输,就可以添加这个 trainsient
key的要求
- HashMap 的 key 可以为 null,但 Map 的其他实现则不行
- 作为 key 的对象,必须实现 hashCode 和 equals,并且 key 的内容不能修改(不可变),如果 key 可变,例如修改了 age 会导致再次查询时查询不到
- key 的 hashCode 应该有良好的散列性
put流程
- HashMap 是懒惰创建数组的,首次使用才创建数组
- 计算索引(桶下标)
- 如果桶下标还没人占用,创建 Node 占位返回
如果桶下标已经有人占用
- 已经是 TreeNode 走红黑树的添加或更新逻辑
- 是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
- 返回前检查数组容量是否超过阈值,一旦超过进行扩容
HashMap扩容机制
默认 HashMap 的长度是 16,loadFactor 负载因子为 0.75,当 table 数组被使用了 75% 以上 或者 某一位置的链表长度大于 8 时,都会扩容为原来的 2 倍。扩容是一个比较消耗资源的操作,需要为数组分配更多的空间,好处就是数组长度更长了,可以使哈希算法更加均匀,碰撞更少。
并发问题
HashMap 多线程操作导致死循环问题
主要原因在于并发下的 Rehash 会造成元素之间会形成一个循环链表。不过,jdk1.8 后解决了这个问题,但还是不建议在多线程下使用 HashMap,还会出现数据错乱的问题;并发环境下推荐使用 ConcurrentHashMap
版权属于:乐心湖's Blog
本文链接:https://xn2001.com/archives/665.html
声明:博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!

One comment
拼