前提准备:4台虚拟机,namenode+datanode1+datanode2+datanode3
顺序不能错!步骤不能漏!已经做过的不用重复做!
配置静态IP
四台虚拟机均需。
cd /etc/sysconfig/network-scripts
vim ifcfg-ens33在末尾追加内容
- IPADDR:修改你目前的IP
- GATEWAY:修改你网关地址,虚拟机一般以 2 结尾,所以修改 92 即可
- DNS1:保持跟上面一样
BOOTPROTO="static"
IPADDR="192.168.92.133"
NETMASK="255.255.255.0"
GATEWAY="192.168.92.2"
DNS1="192.168.92.2"
NM_CONTROLLED=no重启网卡
systemctl restart network.service修改主机名
四台虚拟机均需。
hostnamectl set-hostname namenodehostnamectl set-hostname datanode1hostnamectl set-hostname datanode2hostnamectl set-hostname datanode3修改完要重启。登录后是下图这样的说明修改成功。没成功就多改多重启几次。

配置DNS
四台虚拟机均需。
vi /etc/hosts在末尾追加内容,IP改成你的
192.168.92.133 namenode
192.168.92.134 datanode1
192.168.92.135 datanode2
192.168.92.136 datanode3安装JDK
四台虚拟机均需。
[下载地址](https://ws28.cn/f/5ebbch1i9ig
),里面有 jdk 和 hadoop,一起下载。自己去官方下载也行。
把 jdk-8u291-linux-x64.tar.gz 上传到 /opt
cd /opt
文件拉上去,然后解压
tar -zxvf jdk-8u291-linux-x64.tar.gz修改文件名
mv jdk1.8.0_291 jdk
#忘记了,好像是这样配置环境变量
vi /etc/profile末尾追加内容
export JAVA_HOME=/opt/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar刷新配置文件
source /etc/profile检验
java -version创建用户
四台虚拟机均需。
useradd hadoop
#改密码,看不见的,按就行了,两次,不用管提示
passwd hadoop在 root 用户下操作,意思就是命令之前有 root@namenode
vi /etc/sudoers找到 root ALL=(ALL) ALL
下面添加hadoop ALL=(ALL) ALL
创建 hadoop 有关的目录,赋予所有权
mkdir /home/hadoop/name
mkdir /home/hadoop/data
mkdir /home/hadoop/temp
chown -R hadoop:hadoop /home/hadoop配置SSH
只在 namenode 主机操作
在 hadoop 用户下操作
su hadoop下面的命令是生成公钥密钥,执行后疯狂回车即可。
ssh-keygenssh-copy-id namenode
ssh-copy-id datanode1
ssh-copy-id datanode2
ssh-copy-id datanode3逐个连接测试,输入yes,提示要密码就不对。
ssh localhost
exit
ssh hadoop@namenode
exit
ssh hadoop@datanode1
exit
ssh hadoop@datanode2
exit
ssh hadoop@datanode3安装hadoop
只在 namenode 主机操作
在 root 用户下操作
su root把下载的 hadoop 上传到 /usr/local
cd /usr/local解压
tar -zxvf hadoop-3.1.4.tar.gzchown -R hadoop:hadoop ./hadoop-3.1.4
ln -s /usr/local/hadoop-3.1.4 /usr/local/hadoop测试
/usr/local/hadoop/bin/hadoop version配置 hadoop 核心文件
cd /usr/local/hadoop/etc/hadoop
vi hadoop-env.sh末尾追加内容
export JAVA_HOME=/opt/jdk修改 workers,以前 2.x 版本叫 slaves,现在改了
vi workers
#追加内容
datanode1
datanode2
datanode3追加内容 core-site.xml,hdfs-site.xml,yarn-site.xml
vi core-site.xml
#内容,注意删掉原本的 configuration 标签再粘贴
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/temp</value>
<description>A base for other temporary directories.
</description>
</property>
</configuration>vi hdfs-site.xml
#内容,道理一样
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>namenode:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>vi yarn-site.xml
#内容,道理一样
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>namenode:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>namenode:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>namenode:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>namenode:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>namenode:8088</value>
</property>
</configuration>把文件复制给其他虚拟机,一行一行执行
scp -r /usr/local/hadoop hadoop@datanode1:/usr/local/hadoop-3.1.4
scp -r /usr/local/hadoop hadoop@datanode2:/usr/local/hadoop-3.1.4
scp -r /usr/local/hadoop hadoop@datanode3:/usr/local/hadoop-3.1.4保险起见,再授予一次文件所有权,所有虚拟机都可以执行一遍
chown -R hadoop:hadoop /usr/local/hadoop-3.1.4配置hadoop
四台虚拟机均需。
在 hadoop 用户下操作
su hadoop环境变量
sudo vi ~/.bash_profile
#内容
HADOOP_HOME=/usr/local/hadoop-3.1.4
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME PATH刷新配置
source ~/.bash_profile启动hadoop
在 namenode 执行下面命令
hdfs namenode -formatstart-all.shjps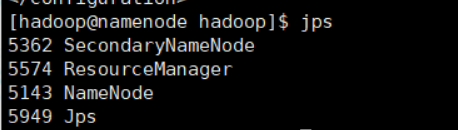
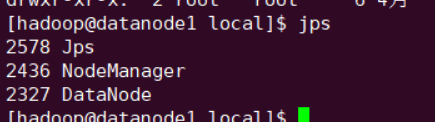
datanode1 ... 2... 3 都在跟着启动,每个虚拟机都试一下 jps
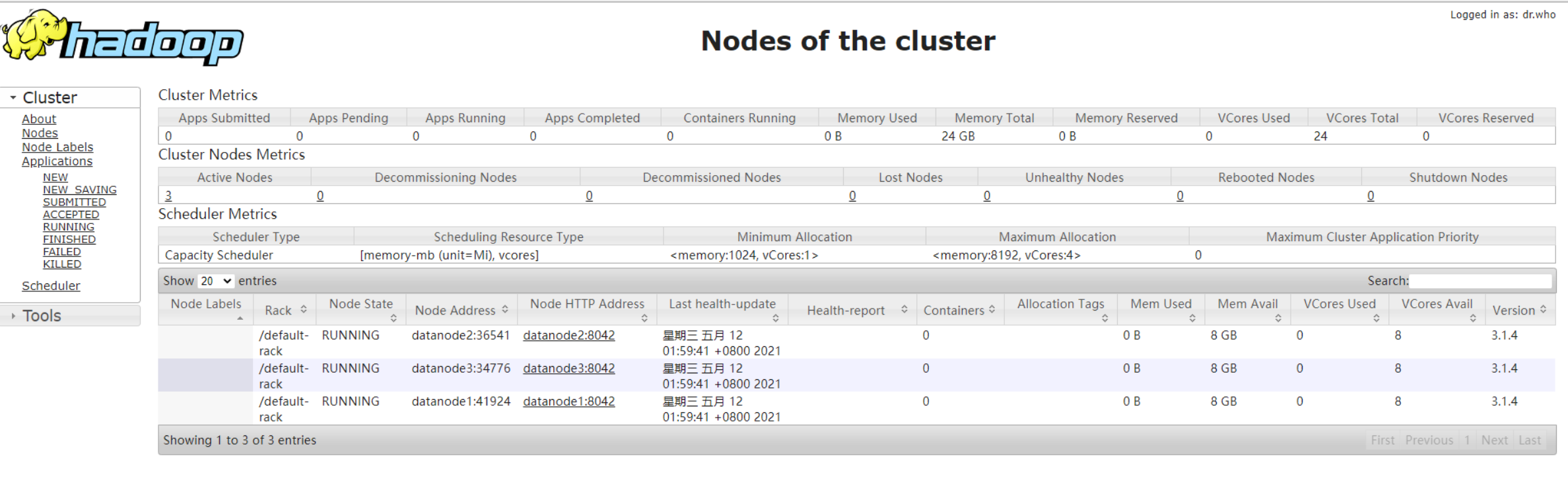
可以在电脑浏览器访问:namenode的ip:9870 namenode的ip:8088
没成功的,肯定是哪里少做多做了。
版权属于:乐心湖's Blog
本文链接:https://xn2001.com/archives/651.html
声明:博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!

2 comments
niu
你还是个学生