初级检索
1. _cat
| API | 简介 |
|---|---|
| GET /_cat/nodes | 查看所有节点 |
| GET /_cat/health | 查看 es 健康状况 |
| GET /_cat/master | 查看主节点 |
| GET /_cat/indices | 查看所有索引 show databases; |
2. 索引文档(CRUD)
保存文档
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1 :在 customer 索引下的 external 类型下保存 1号数据
{
"name":"乐心湖"
}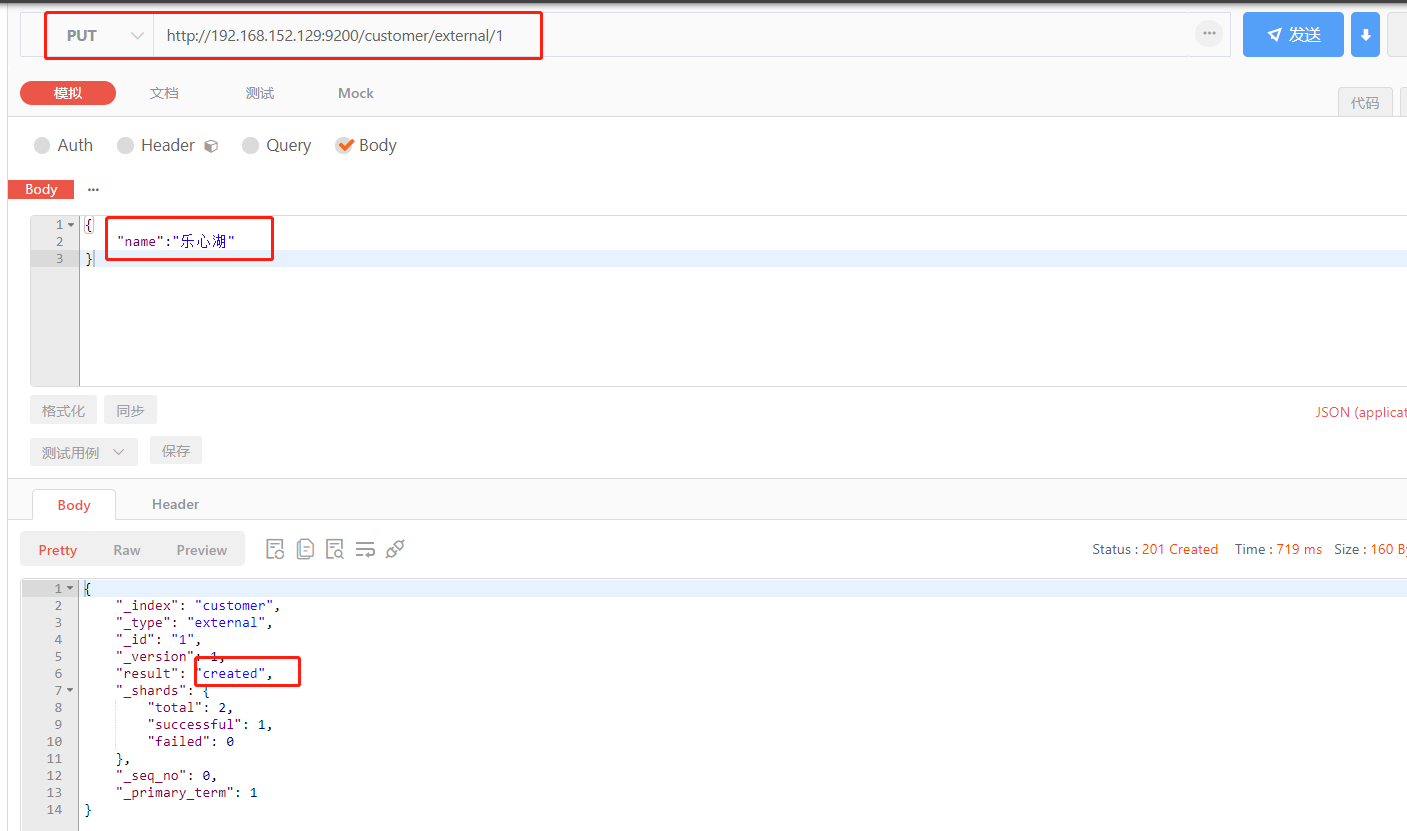
PUT 和 POST 都可以;
POST 可以新增可以修改。可以选择是否指定id,如果不指定id,会自动生成id。指定id就会修改这个数据,并新增版本号;
PUT 可以新增可以修改。PUT必须指定id;由于PUT需要指定id,我们一般都用来做修改操作,不指定d会报错;
查询文档
GET custome/external/1 :在 customer 索引下的 external 类型下查询 1号数据
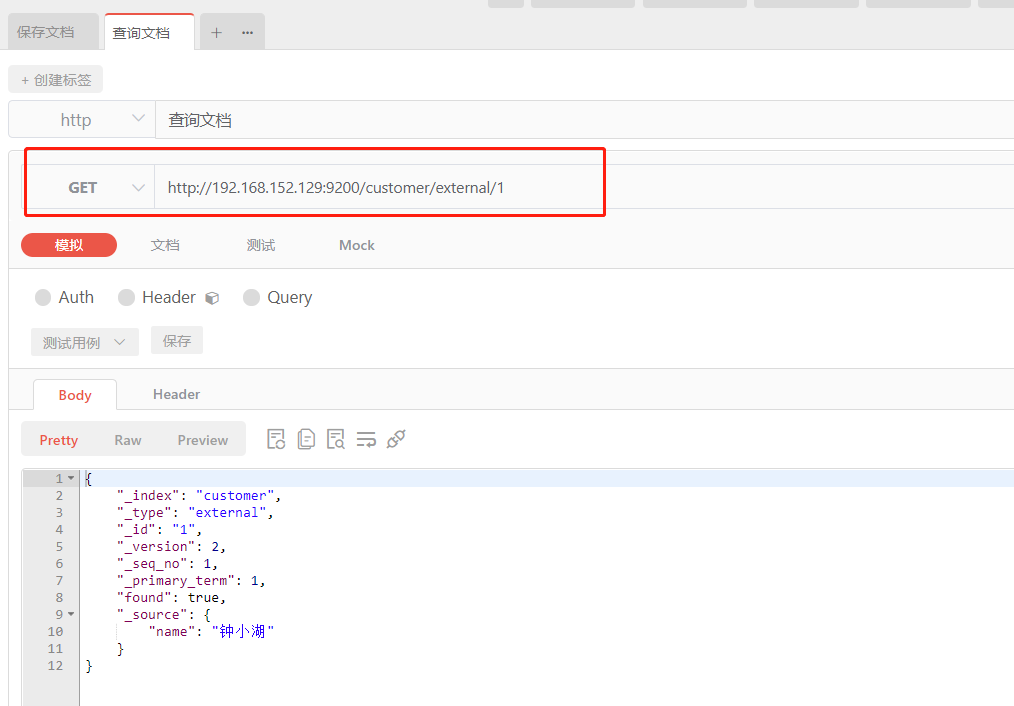
结果分析
{
"_index": "customer", // 索引
"_type": "external", // 类型
"_id": "1", // 记录id
"_version": 2, // 版本号
"_seq_no": 1, // 并发控制字段,每次更新就会+1,用来做乐观锁
"_primary_term": 1, // 同上,主分片重新分配,如重启,就会变化
"found": true,
"_source": {
"name": "钟小湖"
}
}更新文档
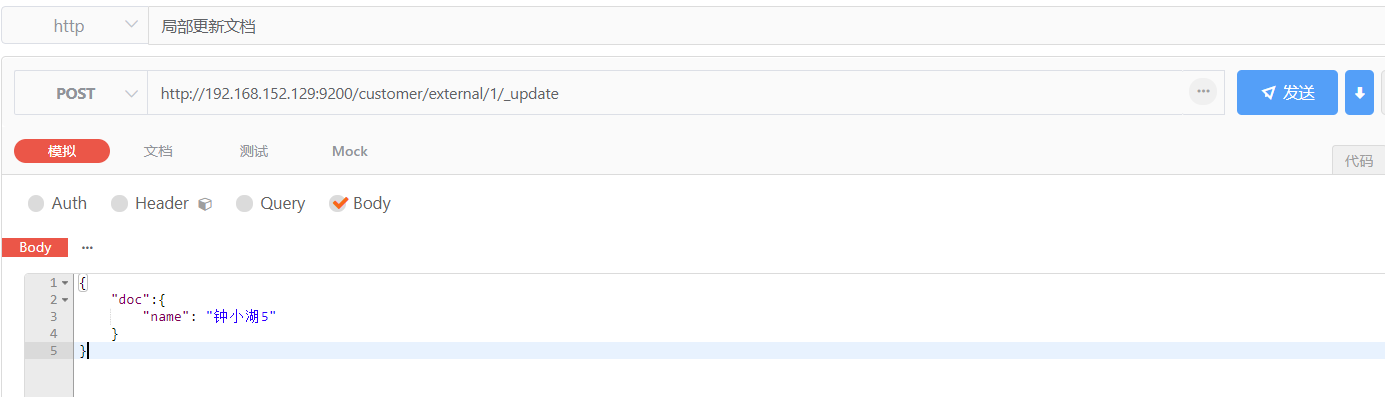
有两种方式,效果一样。
一:POST custome/external/1 ,当带有 _update 时,为局部更新文档,此时的内容格式需要调整,写在 "doc" 里面,例如:
http://192.168.152.129:9200/customer/external/1/_update
{
"doc":{
"name": "钟小湖5"
}
}
二:PUT customer/external/1
删除文档
DELETE customer/external/1
DELETE customer
值得一提的是:
Elasticsearch 没有提供删除类型的API,其实你可以把Type下的所有Document删除掉,也相当于删除了Type
批量保存
POST customer/external/_bulk
这个需要在 Kibana 中使用,数据结构稍有不同
{"index":{"_id":"1"}}
{"name":"钟小湖"}
{"index":{"_id":"2"}}
{"name":"乐心湖"}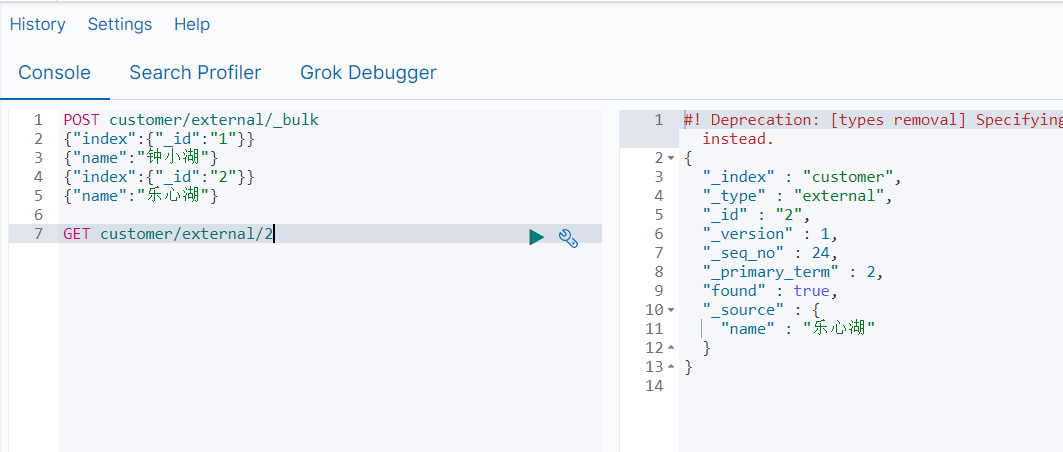
数据格式
{action:{metadata}}\n
{requeestBody}\n
{action:{metadata}}\n
{requesetbod }\n导入样本测试数据,方便后续学习。
POST bank/account/_bulk
https://github.com/elastic/elasticsearch/edit/master/docs/src/test/resources/accounts.json
高级检索
SearchAPi
ES 支持两种基本方式检索:
- 一个是通过使用 REST request URL,发送搜索参数,(uri + 检索参数)
- 另一个是通过使用 REST request bod 来发送他们,(uri + 请求体)
发送请求
GET /bank/_search?q=*&sort=account_number:asc
响应结果
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "40",
"_score" : null,
"_source" : {
"account_number" : 40,
"balance" : 33882,
"firstname" : "Pace",
"lastname" : "Molina",
"age" : 40,
"gender" : "M",
"address" : "263 Ovington Court",
"employer" : "Cytrak",
"email" : "pacemolina@cytrak.com",
"city" : "Silkworth",
"state" : "OR"
},
"sort" : [
40,
40
]
},
...
]The response also provides the following information about the search request:
took– how long it took Elasticsearch to run the query, in millisecondstimed_out– whether or not the search request timed out_shards– how many shards were searched and a breakdown of how many shards succeeded, failed, or were skipped.max_score– the score of the most relevant document foundhits.total.value- how many matching documents were foundhits.sort- the document’s sort position (when not sorting by relevance score)hits._score- the document’s relevance score (not applicable when usingmatch_all)
(1)只有6条数据,这是因为存在分页查询;
(2)详细的字段信息,参照: https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-search.html
- took - Elasticearch执行搜索的时间(毫秒)
- time_ out - 告诉我们搜索是否超时
- _shards - 告诉我们多少个分片被搜索了,以及统计了成功/失败的搜索分片
- hit - 搜索结果
- hits.total - 搜索结果
- hits.hits - 实际的搜索结果数组(默认为前10的文档)
- sort - 结果的排序key (键) (没有则按 score 排序)
- score 和 max score - 相关性得分和最高得分(全文检索用)
HTTP 客户端工具(POSTMAN),get请求不能携带请求体,我们变为 post 也一样的 我们 POST 一个 JSON 风格的查询请求体到 _search API
一旦搜索结果被返回,ES 就完成了这次请求的搜索,并且不会维护任何服务端的资源或者结果的 cursor(游标)
当然你可以用 uri+请求体 进行检索在 Kibana 中使用,也就是第二种方法。
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "age": "desc"},
{ "account_number": "asc" }
]
}Query DSL
基本语法格式
Elasticsearch 提供了一个可以执行查询的Json风格的DSL。这个被称为Query DSL,该查询语言非常全面。
一个查询语句的典型结构
QUERY_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}例子:
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "age": "desc" },
{ "account_number": "asc" }
],
"from": "1",
"size": "2"
}query定义如何查询
- match_all 查询类型(代表查询所有的所有),es 中可以在 query 中组合非常多的查询类型完成复杂查询;
- 除了 query 参数之外,我们也可以传递其他的参数以改变查询结果,如 sort,size;
- from+size 限定,完成分页功能;
- sort排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;
如果针对于某个字段
{
QUERY_NAME:{
FIELD_NAME:{
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}返回部分字段
增加 "_source"
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "age": "desc" },
{ "account_number": "asc" }
],
"from": "1",
"size": "2",
"_source": ["firstname","age"]
}match(匹配查询)
增加 match ,match 返回 age=24 的数据。
GET /bank/_search
{
"query": {
"match": { "age": "24" }
},
"sort": [
{ "account_number": "asc" }
],
"from": "1",
"size": "2",
"_source": ["firstname","age"]
}属性为基本类型(非字符串)时,精确控制
属性为字符串时,全文检索(模糊查询)
GET /bank/_search
{
"query": {
"match": { "address": "mill lane" }
}
}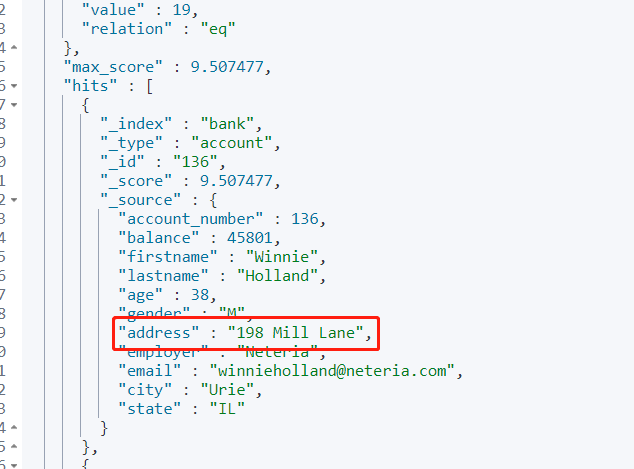
全文检索,最终会按照评分(score)进行排序,会对检索条件进行分词匹配。
match_phrase(短句匹配)
将需要匹配的值当成一整个单词(不分词)进行检索
查处address中包含mill_road的所有记录,并给出相关性得分
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
使用match的keyword
文本字段的匹配,使用keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。
搜不到文档
GET bank/_search
{
"query": {
"match": {
"address.keyword": "990 Mill"
}
}
}一条文档
GET bank/_search
{
"query": {
"match": {
"address.keyword": "990 Mill Road"
}
}
}multi_math(多字段匹配)
state或者address中包含mill,并且在查询过程中,会对于查询条件进行分词。
GET bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": [
"address",
"state"
]
}
}
}bool(复合查询)
复合语句可以合并任何其他查询语句,包括符合语句。这也就意味着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑。
must:必须达到 must 所列举的所有条件
should:应该达到 should 列举的条件,如果达到会增加相关文档的评分,并不会改变查询的结果,如果 query 中只有 should 且只有一种匹配规则,那么 should 的条件就会被作为默认匹配条件而区改变查询结果。
must_not:必须不是指定的情况
GET /bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{"match":{
"age":"38"
}}
],
"should": [
{"match": {
"lastname": "Wallace"
}}
]
}
}
}filter[结果过滤]
并不是所有的查询都需要产生分数,特别是哪些仅用于 filtering 过滤的文档。为了不计算分数,elasticsearch 会自动检查场景并且优化查询的执行。
filter 在使用过程中,并不会计算相关性得分。
GET /bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 30,
"lte": 40
}
}
}
}
}
}
与 must 混用,在此基础上过滤出合适的结果。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "mill"
}}
],
"filter": {
"range": {
"age": {
"gte": 30,
"lte": 40
}
}
}
}
}
}这里先是查询所有匹配 address=mill 的文档,然后再根据 30<=age<=40 进行过滤查询结果
在boolean查询中,
must,should和must_not元素都被称为查询子句 。 文档是否符合每个“must”或“should”子句中的标准,决定了文档的“相关性得分”。 得分越高,文档越符合您的搜索条件。 默认情况下,Elasticsearch返回根据这些相关性得分排序的文档。
must_not子句中的条件被视为“过滤器”。它影响文档是否包含在结果中, 但不影响文档的评分方式。还可以显式地指定任意过滤器来包含或排除基于结构化数据的文档。
term
和match一样。匹配某个属性的值。全文检索字段用 match,其他非text字段匹配用 term
Avoid using the
termquery fortextfields.避免对文本字段使用“term”查询
By default, Elasticsearch changes the values of
textfields as part of [analysis](). This can make finding exact matches fortextfield values difficult.默认情况下,Elasticsearch作为[analysis]()的一部分更改 “text”字段的值。这使得为“text”字段值寻找精确匹配变得困难。
To search
textfield values, use the match.要搜索“text”字段值,请使用匹配。
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/query-dsl-term-query.html
使用 term 匹配查询
GET bank/_search
{
"query": {
"term": {
"address": "mill Road"
}
}
}查询结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
一条也没有匹配到
而更换为match匹配时,能够匹配到32个文档
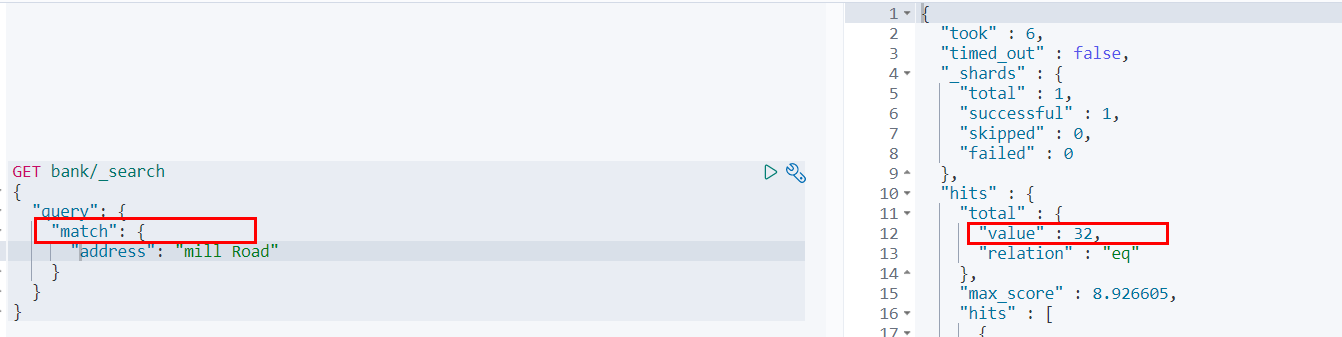
因此,全文检索字段用 match,其他非text字段匹配用 term。
例如:address 用 mathch;age 用 term;
Aggregation(聚合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于SQL Group by和SQL聚合函数。在elasticsearch中,执行搜索返回hits(命中结果),并且同时返回聚合结果,把已响应中的所有hits(命中结果)分隔开。这是非常强大且有效的,你可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果。
基本语法
{
"aggs": {
"my-agg-name": {
"terms": {
"field": "my-field"
}
}
}
}搜索 address 中包含 mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET /bank/_search
{
"query": {
"match": {
"address": "Mill"
}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age"
}
},
"ageAvg": {
"avg": {
"field": "age"
}
}
},
"size": 0
}从结果可以看到,搜索的详细结果 htis 没有展示了,原因是我们加了 "size": 0
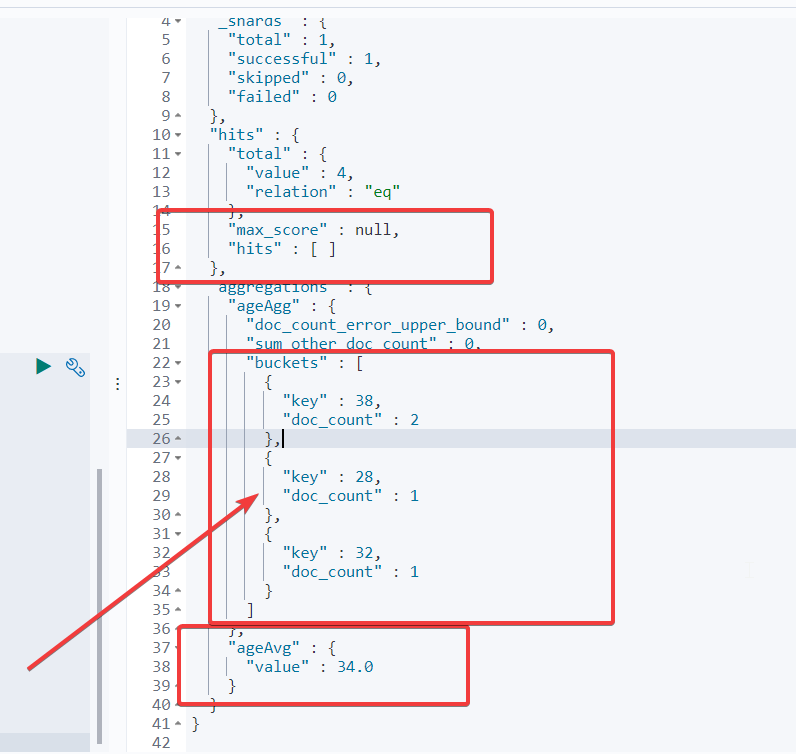
按照年龄聚合,并且求这些年龄段的这些人的平均薪资
相当于在聚合中再添一层聚合
GET /bank/_search
{
"aggs": {
"ageAgg": {
"terms": {
"field": "age"
},
"aggs": {
"balanceAgg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}结果:31岁的人有61个,他们的平均工资为28312。
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 463,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"balanceAgg" : {
"value" : 28312.918032786885
}
},
...
]
}
}查出所有年龄分布,并且这些年龄段中性别M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET /bank/_search
{
"aggs": {
"ageAgg": {
"terms": {
"field": "age"
},
"aggs": {
"genderAgeAgg": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"balanceGenderAgeAgg": {
"avg": {
"field": "balance"
}
}
}
},
"balanceAgeAgg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}结果
{
"key" : 31,
"doc_count" : 61,
"balanceAgeAgg" : {
"value" : 28312.918032786885
},
"genderAgeAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M",
"doc_count" : 35,
"balanceGenderAgeAgg" : {
"value" : 29565.628571428573
}
},
{
"key" : "F",
"doc_count" : 26,
"balanceGenderAgeAgg" : {
"value" : 26626.576923076922
}
}
]
}
},Mapping
Maping 是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。
使用maping来定义
- 哪些字符串属性应该被看做全文本属性(full text fields);
- 哪些属性包含数字,日期或地理位置;
- 文档中的所有属性是否都嫩被索引(all 配置);
- 日期的格式;
- 自定义映射规则来执行动态添加属性;
查看mapping信息 GET bank/_mapping
创建索引并指定映射
PUT /my_index
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
},
"name": {
"type": "text"
}
}
}
}{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_index"
}查看映射
GET /my_index/_mapping
// 结果
{
"my_index" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"email" : {
"type" : "keyword"
},
"name" : {
"type" : "text"
}
}
}
}
}添加新的字段映射
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}这里的 "index": false,表明新增的字段不能被检索,只是一个冗余字段。
更新映射
对于已经存在的字段映射,我们不能更新。更新必须创建新的索引,进行数据迁移。
数据迁移
例如我们想把索引 bank 中的 age 修改为 integer
就需要创建一个新的索引,指定号映射类型
PUT /newbank
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "keyword"
},
"email": {
"type": "keyword"
},
"employer": {
"type": "keyword"
},
"firstname": {
"type": "text"
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "keyword"
}
}
}
}由于我们的数据是在 /bank/account 下,所有需要添加 "type": "account"
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}查看新的索引信息
GET /newbank/_search
版权属于:乐心湖's Blog
本文链接:https://xn2001.com/archives/624.html
声明:博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
